Biteable مقابل InVideo: مقارنة الميزات في لمحة
نظرة عامة جنبًا إلى جنب
| الميزة | Biteable | InVideo |
|---|---|---|
| الذكاء الاصطناعي الأساسي | AVA (خاص) — مسار من النص إلى الفيديو | أكثر من 200 نموذج: Sora 2، Veo 3.1، Kling 3.0 |
| قاعدة المستخدمين | أكثر من 9 ملايين مستخدم، وأكثر من 10,000 شركة | أكثر من 50 مليون صانع محتوى عالميًا |
| أقصى مدة فيديو | 10 دقائق (Pro)، 20 دقيقة (Premium) | 30 دقيقة من موجّه واحد |
| أفاتار الذكاء الاصطناعي | واقعية + متحركة، رفع مخصص، 20–40 مقطعًا/شهر | 4–40 أفاتار + AI Twins من التسجيلات |
| الصوت | أكثر من 50 صوت ذكاء اصطناعي، ترجمة متعددة اللغات | استنساخ الصوت من مقطع 30 ثانية، تكامل ElevenLabs |
| القوالب | آلاف عبر أكثر من 15 فئة | أكثر من 7,000 في InVideo Studio |
| وسائط المخزون | Storyblocks + Pexels، موسيقى خالية من حقوق الملكية | iStock + Storyblocks (100–1,000 مقطع/خطة) |
| جودة التصدير | HD 1080p (Pro)، 4K (Premium) | حتى 4K، بدون علامة مائية في الخطط المدفوعة |
| العلامة التجارية | علامة تجارية تلقائية من الرابط، 20 ملف علامة تجارية، خطوط مخصصة | علامة تجارية أساسية |
| تسجيل الشاشة | نعم (مدمج) | لا |
| تحليلات الفيديو | المشاهدات، التفاعل، بيانات الموقع | أساسية فقط |
| تطبيق الجوال | لا | نعم (الخطط المدفوعة) |
| ملقّن النص (Teleprompter) | لا | لا |
| سعر البداية (سنوي) | 15 دولارًا/شهر (Pro) | 25 دولارًا/شهر (Plus) |
Biteable: ما هو فعليًا
يضع Biteable نفسه كأسهل صانع فيديو بالذكاء الاصطناعي للشركات. يأخذ محرك AVA الموجّه النصي عبر سير عمل منظّم — تختار نوع الفيديو (شرح، إعلان، إعلان جديد، عرض منتج، إعلان توظيف، قائمة مرقّمة)، وتقدّم معلومات نشاطك التجاري، ويولّد AVA نصًا ولوحة قصصية وفيديو نهائيًا بعناصر بصرية وتعليق صوتي وموسيقى متناسقة. تسحب ميزة العلامة التجارية التلقائية ألوانك وخطوطك وشعارك من رابطك، مما يوفر وقت إعداد ملموسًا للفرق التي تدير علامات تجارية متعددة.
إلى جانب AVA، يمكنك البدء من قالب أو لوحة فارغة أو تسجيل شاشة أو حتى رابط صفحة ويب — يحوّل Biteable المقالات مباشرة إلى مقاطع فيديو، وهو أمر مفيد حقًا لإعادة توظيف المحتوى. وتكمل التحليلات المدمجة (عدد المشاهدات، التفاعل، الموقع) وتسجيل الشاشة ما هو أداة أعمال أكثر اكتمالًا مما تبدو للوهلة الأولى.
InVideo: ما هو فعليًا
يتّبع InVideo النهج المعاكس. فبدلًا من ذكاء اصطناعي خاص واحد، يوجّه موجّهاتك عبر أي نموذج متقدم يُنتج أفضل نتيجة لحالة استخدامك — Sora 2، Veo 3.1، Kling 3.0، Pixverse، Hailuo، وأكثر من 190 نموذجًا آخر. تكتب موجّهًا، وتختار جمهورك ومنصتك، ويولّد الذكاء الاصطناعي النص والعناصر البصرية والتعليق الصوتي والترجمات والموسيقى. ثم يمكنك التكرار بإعطاء أوامر بلغة طبيعية: "اجعل المقدمة أكثر حيوية" أو "استبدل اللقطات المخزنة بشيء أكثر سينمائية."
يقدّم InVideo أيضًا AI Twins — نسخ رقمية منك تُنشأ من رابط YouTube أو تسجيل مرفوع — واستنساخ الصوت من مقطع صوتي مدته 30 ثانية. وبالنسبة لصنّاع المحتوى الذين يريدون محتوى ذكاء اصطناعي مخصصًا على نطاق واسع دون تسجيل أنفسهم في كل مرة، فهذا هو الخيار الأكثر قدرة المتاح.
![[object Object]](/blog/images/airtable/section1-biteable-vs-invideo-2026-ai-video-maker-worth-money.webp)
قدرات الذكاء الاصطناعي: AVA من Biteable مقابل النموذج المتعدد لـ InVideo
كيف يعمل AVA من Biteable
AVA ذكاء اصطناعي موجَّه ومنظَّم. تختار من بين 11 نوعًا من الفيديو — شروحات الأعمال، وعروض المنتجات، وإعلانات الفعاليات، وقوائم النصائح، وإعلانات التوظيف، وغيرها — ثم تقدّم سياق نشاطك التجاري. ويولّد AVA من هناك لوحة قصصية وفيديو كاملين. هذه القابلية للتنبؤ نقطة قوة حقيقية: تعرف ما ستحصل عليه، والمُخرَج متسق مع العلامة التجارية باستمرار، ومنحنى التعلّم ضئيل. أما المقابل فهو المرونة الإبداعية — إذ يعمل AVA ضمن قوالب وهياكل محددة بدلًا من توليد محتوى مفتوح من موجّه حر.
تتضمن مكتبة الأفاتار في Biteable خيارات واقعية ومتحركة على حد سواء، ويمكنك رفع صورتك الخاصة لإنشاء أفاتار مخصص. تتضمن خطة Pro عشرين مقطع أفاتار شهريًا، وتتضمن Premium أربعين.
كيف يعمل نهج النموذج المتعدد في InVideo
يقبل وكيل v4 من InVideo موجّهًا نصيًا حرًا ويوجّهه عبر أنسب النماذج من مكتبته التي تضم أكثر من 200 نموذج. والنتيجة فيديو كامل — نص، وعناصر بصرية، وتعليق صوتي، وترجمات، وموسيقى — يُنشأ في مرور واحد، بمدة تصل إلى 30 دقيقة. ويمكنك التكرار بأسلوب حواري بعد الإنشاء، مما يجعل التعديلات المعقدة أسرع من المحرر التقليدي.
ميزة AI Twins هي أكثر قدرات InVideo تميّزًا. تُنشئ نسخة رقمية منك من تسجيل موجود أو رابط YouTube، ويستطيع ذلك الأفاتار تقديم أي نص بصوتك وهيئتك. واستنساخ الصوت من مقطع مدته 30 ثانية، مع تكامل ElevenLabs للتوليف عالي الجودة، يعني أن محتوى الذكاء الاصطناعي الخاص بك يمكن أن يبدو أصيلًا كأنه أنت حتى عندما لم تسجّل أي شيء.
أين يفوز كلٌّ منهما
يفوز Biteable في الاتساق والبساطة. فإذا كنت بحاجة إلى فريق من خمسة مسوّقين لإنتاج مقاطع فيديو متسقة مع العلامة التجارية دون تدريب أو تجريب، فإن سير عمل AVA الموجّه هو الخيار الصحيح. فكل فيديو يبدو وكأنه صادر من الدليل نفسه.
يفوز InVideo في القدرة والحجم. فإذا كنت بحاجة إلى نماذج ذكاء اصطناعي متقدمة، واستنساخ الصوت، وإنشاء فيديو مدته 30 دقيقة، والقدرة على التكرار عبر اللغة الطبيعية، فإن InVideo متقدم. كما يعني نهج النموذج المتعدد أن InVideo يستوعب تلقائيًا الاختراقات الجديدة في الذكاء الاصطناعي فور إطلاقها — فلا داعي لانتظار المنصة كي تبني نسختها الخاصة.
![[object Object]](/blog/images/airtable/section2-biteable-vs-invideo-2026-ai-video-maker-worth-money.webp)
تفصيل الأسعار: ما تدفعه فعليًا على كل منصة
الفجوة المشتركة بين المنصتين
لم يُصمَّم Biteable ولا InVideo لصنّاع المحتوى الذين يريدون الظهور أمام الكاميرا بأنفسهم. فكلاهما يعتمد بشدة على أفاتار الذكاء الاصطناعي واللقطات المخزنة والعناصر البصرية المؤتمتة. وبالنسبة للمدربين والمستشارين والعلامات التجارية الشخصية حيث يكون جوهر الفيديو هو ثقة الجمهور — لا مجرد حجم المحتوى — فهذا قيد ذو مغزى. فأفاتار الذكاء الاصطناعي لا تبني الصلة نفسها التي يبنيها شخص حقيقي ينظر إلى العدسة.
لا تتضمن أيٌّ من المنصتين ملقّن نص. فإذا أردت تسجيل نفسك وأنت تتحدث بثقة أمام الكاميرا، فستحتاج إلى أداة منفصلة لذلك، مما يعني سير عمل مجزأً واشتراكًا إضافيًا.
ماذا يفعل BIGVU بدلًا من ذلك
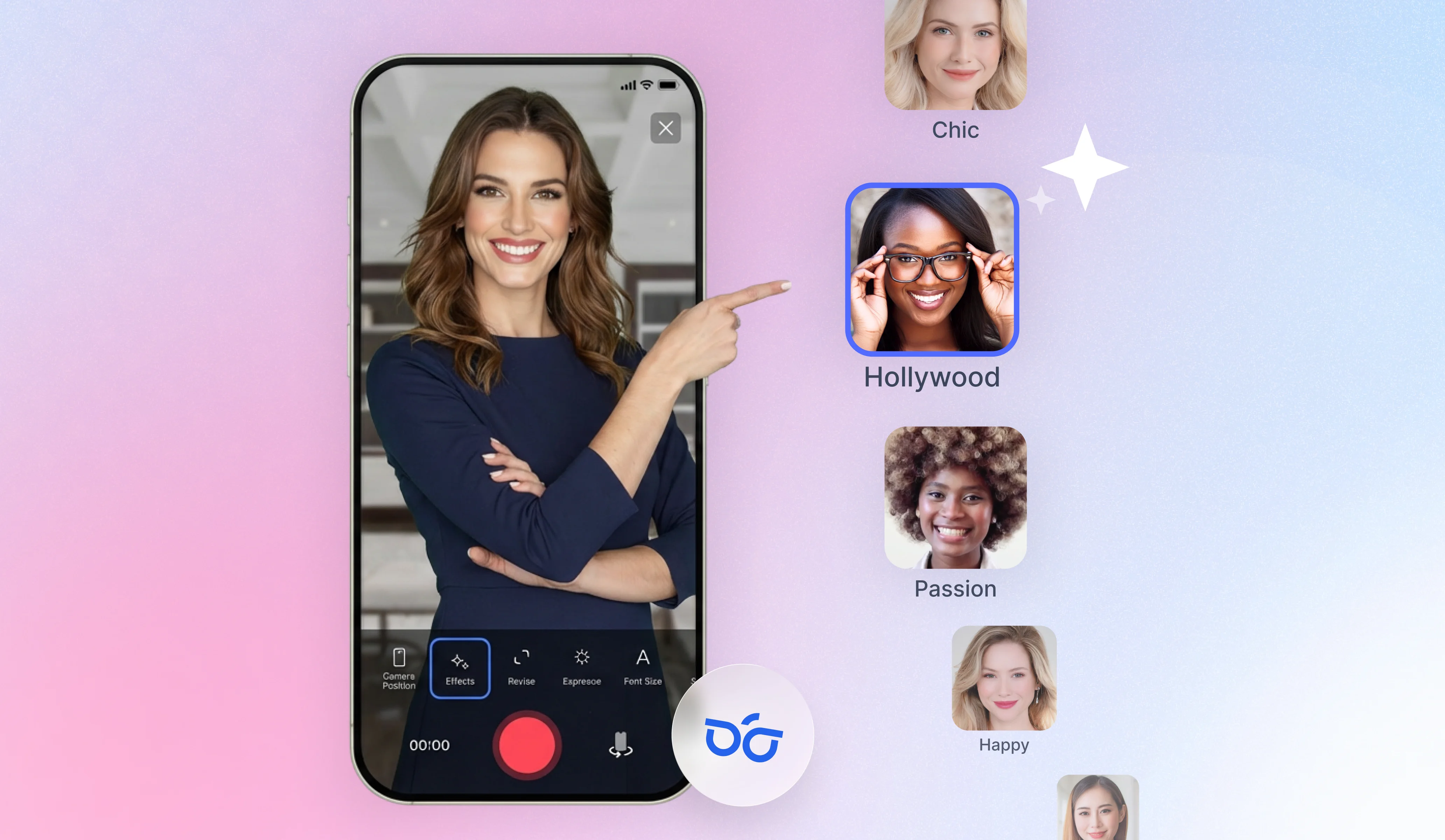
بُني BIGVU للمحتوى الذي يظهر فيه إنسان أمام الكاميرا. يمرّر ملقّن النص المدمج النصَّ أمام العدسة مباشرة لتحافظ على تواصل بصري مباشر مع جمهورك — متاح على iOS وAndroid. ويولّد كاتب النصوص بالذكاء الاصطناعي نصًا كاملًا من أي موضوع في ثوانٍ، ويُغذّى مباشرة في ملقّن النص لسير عمل سلس من التسجيل إلى النشر.
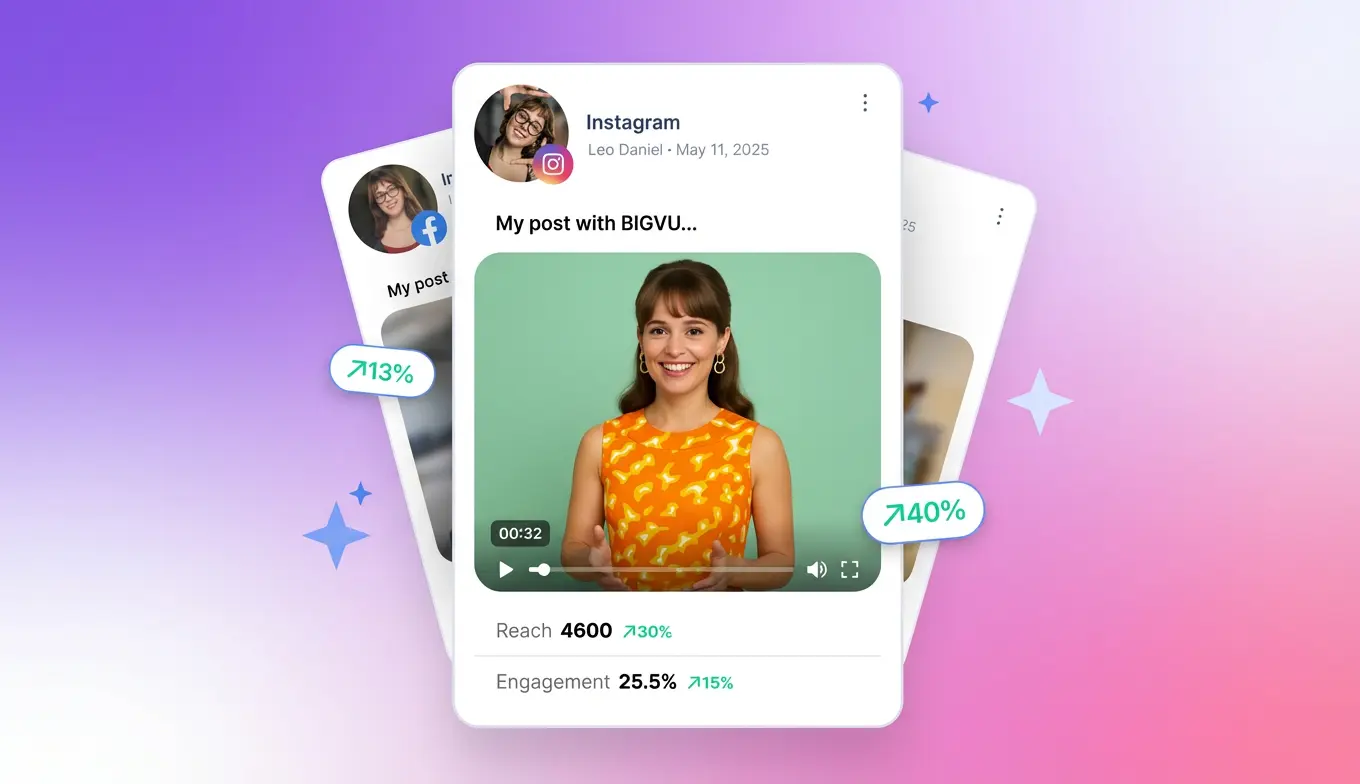
بعد التسجيل، يضيف BIGVU تسميات توضيحية تلقائية بخطوط وألوان علامتك التجارية، ويطبّق مجموعة علامتك التجارية على كل فيديو تلقائيًا، ويولّد مقاطع قصيرة من المحتوى الطويل عبر Auto-Shorts. وتحوّل صفحات هبوط الفيديو المزوّدة بأزرار CTA مخصصة كل فيديو إلى أصل لتوليد العملاء المحتملين بدلًا من مجرد منشور على وسائل التواصل. كما يدعم BIGVU البث المباشر مباشرة إلى YouTube وLinkedIn وFacebook — دون الحاجة إلى مفتاح بث.
واقع الأسعار
يبدأ BIGVU من 8 دولارات/شهر ويشمل ملقّن النص، وإنشاء النصوص بالذكاء الاصطناعي، والتسميات التوضيحية التلقائية، واستنساخ الصوت، وجدولة وسائل التواصل مع ما يصل إلى 20 حسابًا متصلًا. أما المستوى المماثل من Biteable (Premium، مع التسميات التوضيحية) فيبلغ 49 دولارًا/شهر. ويبلغ InVideo Plus خمسة وعشرين دولارًا/شهر لكنه يفتقر تمامًا إلى ملقّن النص. وبالنسبة لصنّاع المحتوى الذين يظهرون أمام الكاميرا، يغطّي BIGVU جزءًا أكبر من سير العمل بتكلفة أقل.
![[object Object]](/blog/images/airtable/section3-biteable-vs-invideo-2026-ai-video-maker-worth-money.webp)
لماذا يحتاج صنّاع المحتوى أمام الكاميرا إلى أداة مختلفة تمامًا
الفجوة المشتركة بين المنصتين
لم يُصمَّم Biteable ولا InVideo لصنّاع المحتوى الذين يريدون الظهور أمام الكاميرا بأنفسهم. فكلاهما يعتمد بشدة على أفاتار الذكاء الاصطناعي واللقطات المخزنة والعناصر البصرية المؤتمتة. وبالنسبة للمدربين والمستشارين والعلامات التجارية الشخصية حيث يكون جوهر الفيديو هو ثقة الجمهور — لا مجرد حجم المحتوى — فهذا قيد ذو مغزى. فأفاتار الذكاء الاصطناعي لا تبني الصلة نفسها التي يبنيها شخص حقيقي ينظر إلى العدسة.
لا تتضمن أيٌّ من المنصتين ملقّن نص. فإذا أردت تسجيل نفسك وأنت تتحدث بثقة أمام الكاميرا، فستحتاج إلى أداة منفصلة لذلك، مما يعني سير عمل مجزأً واشتراكًا إضافيًا.
ماذا يفعل BIGVU بدلًا من ذلك
بُني BIGVU للمحتوى الذي يظهر فيه إنسان أمام الكاميرا. يمرّر تلقين BIGVU المدمج النصَّ أمام العدسة مباشرة لتحافظ على تواصل بصري مباشر مع جمهورك — متاح على iOS وAndroid. ويولّد كاتب النصوص بالذكاء الاصطناعي نصًا كاملًا من أي موضوع في ثوانٍ، ويُغذّى مباشرة في ملقّن النص لسير عمل سلس من التسجيل إلى النشر.
بعد التسجيل، يضيف BIGVU تسميات توضيحية تلقائية بخطوط وألوان علامتك التجارية، ويطبّق مجموعة علامتك التجارية على كل فيديو تلقائيًا، ويولّد مقاطع قصيرة من المحتوى الطويل عبر Auto-Shorts. وتحوّل صفحات هبوط الفيديو المزوّدة بأزرار CTA مخصصة كل فيديو إلى أصل لتوليد العملاء المحتملين بدلًا من مجرد منشور على وسائل التواصل. كما يدعم BIGVU البث المباشر مباشرة إلى YouTube وLinkedIn وFacebook — دون الحاجة إلى مفتاح بث.
واقع الأسعار
يبدأ BIGVU من 8 دولارات/شهر ويشمل ملقّن النص، وإنشاء النصوص بالذكاء الاصطناعي، والتسميات التوضيحية التلقائية، واستنساخ الصوت، وجدولة وسائل التواصل مع ما يصل إلى 20 حسابًا متصلًا. أما المستوى المماثل من Biteable (Premium، مع التسميات التوضيحية) فيبلغ 49 دولارًا/شهر. ويبلغ InVideo Plus خمسة وعشرين دولارًا/شهر لكنه يفتقر تمامًا إلى ملقّن النص. وبالنسبة لصنّاع المحتوى الذين يظهرون أمام الكاميرا، يغطّي BIGVU جزءًا أكبر من سير العمل بتكلفة أقل.

أي منصة ينبغي أن تختار؟
اختر Biteable إذا...
كنت فريق تسويق أو شركة تنتج مقاطع فيديو بقوالب ذات طابع تجاري — شروحات، ومحتوى تدريبي، واتصالات داخلية، وإعلانات اجتماعية — بحجم ثابت. فسير عمل AVA في Biteable، والعلامة التجارية التلقائية من الرابط، والتعاون الجماعي (حتى 3 مستخدمين في Premium)، والتحليلات المدمجة تجعله أكثر أدوات الأعمال اكتمالًا بين الثلاثة. ويعمل نهج الذكاء الاصطناعي الموجّه جيدًا للفرق التي ليس فيها كل شخص محرر فيديو.
اختر InVideo إذا...
كنت وكالة محتوى أو صانع محتوى أو منتِجًا بحجم كبير يحتاج إلى نماذج ذكاء اصطناعي متقدمة، واستنساخ الصوت، والقدرة على توليد محتوى طويل بسرعة. فمنصة InVideo متعددة النماذج، وإنشاء فيديو ذكاء اصطناعي مدته 30 دقيقة، وAI Twins، والتكرار باللغة الطبيعية تجعله أكثر أدوات الذكاء الاصطناعي الخالصة قدرة المتاحة. وتقبّل أن نظام الأرصدة يتطلب تخطيطًا للميزانية، وأن منحنى التعلّم في InVideo Studio أكثر انحدارًا من Biteable.
اختر BIGVU إذا...
كنت مدربًا أو مستشارًا أو رائد أعمال أو علامة تجارية شخصية حيث يكون جوهر الفيديو كله هو وجهك وصوتك وسلطتك. فملقّن النص في BIGVU، وكتابة النصوص بالذكاء الاصطناعي، والتسميات التوضيحية التلقائية، ومجموعات العلامة التجارية مبنية لسير العمل أمام الكاميرا الذي لا يدعمه Biteable ولا InVideo. فإذا كانت ثقة الجمهور هي الهدف — لا مجرد إنتاج المحتوى — فإن BIGVU هو الأداة الصحيحة.
هل يمكنك استخدام أكثر من أداة؟
نعم، والكثير من صنّاع المحتوى يفعلون ذلك. إعداد شائع: BIGVU للمحتوى الرسمي أمام الكاميرا (نصائح التدريب، والريادة الفكرية، والعروض التوضيحية)، وInVideo أو Biteable للأصول الاجتماعية المُنتَجة بالذكاء الاصطناعي أو الإعلانات أو المحتوى المُعاد توظيفه. تحلّ الأدوات مشكلات مختلفة ولا تتنافس فعليًا على حالة الاستخدام نفسها بمجرد أن تفهم ما بُني كلٌّ منها لأجله بالفعل.